Assetgraph - Optimization Framework for Web Pages and Applications - Interview with Peter Müller
If you have written a web application or site, you have had to deal with various assets like images, fonts, HTML, JavaScript code, whatnot. It’s not a simple task to keep it all organized. This is why we have tools like webpack↗, browserify↗, or jspm↗ after all.
Today I’m interviewing Peter Müller↗, the author of AssetGraph↗, a tool fitting this category. Read on to learn more about the problem and how the tool solves it in a rather unique way.
Can you tell a bit about yourself?#

I am a seasoned front-end developer with lots of experience in developing high usage productivity applications that drive daily workflows. I’ve focused my attention on the problems surrounding development and build tooling for web sites for a long time and have gained an ever-increasing appreciation of simplicity wherever it can be found.
I am a maintainer of the Assetgraph↗ project, authored one-color↗ and contribute to Mocha↗ and Unexpected↗. I recently had my first child, dealt with cancer, and became the owner of a garden, where I hope to put my feet up and relax once in a while.
How would you describe Assetgraph to someone who has never heard of it?#
Assetgraph is a dependency graph that instantiates full data models of all types of typical web assets; HTML, CSS, JavaScript, images and so on. It also comes with the ability to automatically populate this dependency graph by static analysis and crawling of the found dependencies.
To make this graph model useful it has a query language to find assets (nodes) or relations (edges), a transform pipeline to chain modifications of the graph and many curated graph transformations that all focus on common web performance optimizing tasks.
In itself Assetgraph is not useful to the common web developer, but it enables tool developers to take advantage of a full and consistent data model that has a larger scope than any other build tool out there. Let’s call it a toolmakers toolbox.
The really interesting applications are in the specific opinionated tool implementations and the API they expose to the end-user.
How does Assetgraph work?#
There is a certain life cycle that usually makes sense for most Assetgraph based tools:
1. Loading#
Load in some initial assets, entry points of your website like index.html, webmanifest.json, or similar. You can load any number of asset entry points into the graph using the loadAssets transform↗. At this point these assets are nodes without any relation in the dependency graph. To set up the relations between the assets you need to use the populate transform↗.
2. Expanding the graph by crawling#
Populating the graph with a populate() call will start a deep traversal of all outgoing relations to other assets. So if we start the graph with index.html, populate() will find all outgoing anchors to other pages, HTML script tags, style tags, images, RSS feeds, and so forth.
For each of these it will recursively expand their dependencies and keep going until there are no more or it hits a stop condition. If you just let it run unlimited it has the potential to start scraping the entire internet, which I don’t recommend. ;)
This is where the query model comes into play. By passing a query into the populate transform, only assets or relations matching that query will be populated in the graph. A good starter query is { followRelations: { crossorigin: false }} in case your focus is a build system.
This will basically give you a fully populated graph of all your local files if you started with file:///project/index.html, but you could just as well start it off with a URL to a website and get a graph of all its same-origin dependencies.
3. Transforming the graph#
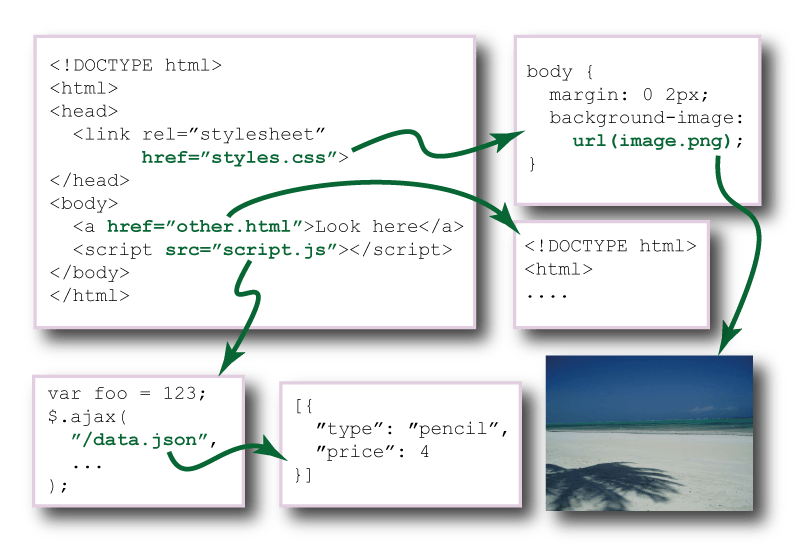
Now you have a fully populated graph model of your code, and this is where the fun starts. Using the transform pipeline you can queue transformations to run on the graph. If you want to rename a file, change its URL with asset.url = 'foo.html'. As a result all relations pointing to it will be updated.
If you want to inline some relations based on the target assets file size, call relation.inline(). There is a long list of available transformations↗ to do these common tasks.
In the end, when you have made all your modifications, you can write the contents of the graph to disk, use it from memory or whatever you can come up with.
Writing your own transformations is relatively straight forward, since the data models are kind of standard these days. HTML is is modeled using jsdom, so you can simply traverse DOM as you are used to. CSS is modeled with the PostCSS data model and JavaScript with Esprima. So you have raw access to the bare metal if you need to, but can still reap all the benefits from the high level modeling.
How does Assetgraph differ from other solutions?#
I am not aware of any project with a scope comparable to core Assetgraph, but I can compare Assetgraph-builder↗ to other projects. Assetgraph-builder is the teams opinionated take on what a web performance optimizing build tool should do, so it comes with all the bells and whistles and attempts to expose a very powerful set of functionality with a focus on simple configuration.
From a build system perspective I’d say the main difference between Assetgraph and other solutions is the scope of what the model tries to cover. Build tools come in lots of varieties, but what most other tools have in common is that to use them you have to adapt your code and development environment for the tool.
With Assetgraph we have a core belief that the tool should not dictate your code. It should instead be able to understand your code like a browser can. This makes a big difference in how you develop. Using Assetgraph you can write a web page like you did in the 90’s. Just make pages, include scripts, reference images etc.
With Assetgraph you don’t think about optimization, and instead focus on making it work in your browser. Then, when you are ready to deploy, you point Assetgraph-builder at your index file and deploy the optimized website that comes out at the other end.
The way Assetgraph works is a stark contrast to all other tools that has you build things in pieces and the tool must assemble things for you before you even have a working web page.
In this way Assetgraph gives you an independence of your tool chain which other tools can’t. If all tools took a similar approach to not dictating how you assemble your code, tools could actually be fully interoperable and be chained together with ease because they would all work with the same data model, a full dependency graph of the entire website.
Other dependency graph based tools, like Browserify, systemjs-builder and webpack have the potential to come close, but as long as they limit their entry point to JavaScript they will always have to expose this leaky abstraction where the user needs to have a environment variable switch between development and production code.
A really big difference is that having the entire scope of your site automatically discovered and modeled on a high level, is that a lot of configuration that you see in other tools simply disappears. File based tools like Grunt, Gulp, Broccoli or even Make, make you configure manifests of files that someone needs to maintain the correct order of. Assetgraph simply finds these things itself.
I’ve seen Gruntfiles where I could literally remove 80-90% of the configuration and replace it with a call to Assetgraph-builder or grunt-reduce↗, which is a Grunt wrapper I wrote for that audience. This simplicity is a thing we focus on keeping across all our transforms and tools. We only want to expose the “what”, not the “how” of operations.
The feature set Assetgraph comes with is also quite impressive in its range and stability compared to other tools. Being able to automatically generate shared bundles across pages by taking advantage of the knowledge of multiple html entry points is something I haven’t seen anywhere else.
Another example is automated spriting, where you work with your raw images as CSS backgrounds in development and just append the URL with ?sprite=spriteName and you get a sprite sheet and all image references updates automatically. The ability to populate external dependencies outside of your own code, to check subresource integrity hashes, update URL’s based on 301 redirects, warn about 404’s, inject them for external critical resources like Web Fonts are examples of further functionality.
Some things just become so much simpler when you are working with a dependency graph. I have looked on in sadness while file based tools like grunt-filerev has struggled to fix bugs and new ones just kept popping up, while we’ve been able to have consistent file hashing across an entire site with what is almost a one-liner. I hope more tools will start taking advantage of dependency graphs in the future.
Why did you develop Assetgraph?#
As most other projects we created Assetgraph to scratch an itch. Back in around 2007 Andreas Lind Petersen↗ and I were working for an atypical web hosting company that was investing heavily in developing their own solutions for webmail, calendaring, blog creation, galleries etc.
These were all fairly large and complex web applications with heavy use of lots of CSS and JavaScript. At the same time awareness was growing about web performance and the lack thereof as Steve Souders↗ had released his inital research results and the resulting 10 rules for better web performance.
Since we had a lot of users on each of our apps and these apps were driving people’s every day communication for work and play, we took performance seriously. At the time our most used app was simply loading blocking script tags in order, CSS nicely divided into multiple requests and so forth. A load performance nightmare. This was further complicated by the app not being single page like in these modern times, but a frameset with multiple pages that had a set of common dependencies.
We iterated through a number of build systems. At the time the best thing available was Yahoo Builder with its Java dependency, massive XML configuration and slowness. Later we tried Make files for bundling and eventually ended up with a hybrid Makefile and Perl script.
At this point we had added our own custom syntax for a JavaScript dependency with // INCLUDE 'foo.js' (I think, long time ago), which would then be picked up by the scripts and in development flattened out to a number of script tags (source maps didn’t exist), but in production it would bundle things together. We ran into all the same problems that Grunt and Gulp plugins have done historically and were never quite satisfied with being stuck with file and string manipulation.
Then Node.js came around, and immediately some really useful modules started becoming available. jsdom, CSSOM and UglifyJS provided ASTs for their respective data model. So Andreas had this brilliant idea of using a graph model to describe the assets and their relations. This was still quite early, I think the first release of Assetgraph came out half a year before Grunt.
In the beginning it was crude and only had a few use cases like bundling and file renaming, only worked with our code and assumed a lot of things. Since then we saw more and more of the value of having a graph model and started separating the core functionality from the build specific ones, creating Assetgraph-builder for our specific purposes, while Assetgraph was getting trimmed down to become more of a tool collection that one could assemble in many ways.
Since then Assetgraph has been driving the web front-end builds of every web application at that web hosting company, and is even used to optimize customer websites created through a “drag and click your own website”-application.
What next?#
We’re preparing a new major release that has updated old and stale dependencies with newer ones, putting Assetgraph on par with other current tools. We were running our own fork of jsdom, which has now been deprecated and replaced with the latest jsdom. CSSOM was replaced with PostCSS and the UglifyJS AST with Esprima.
We’ve killed a lot of features and support for obscure cases that were primarily interesting for internal reasons at that web hosting company. So the upcoming release is simpler to use and has less code to read and maintain.
We’re changing our focus from trying to do everything ourself to offloading some work to other tools that fit into the Assetgraph model in a collaborative way. There is now a SystemJS integration which offloads the complexity of modeling SystemJS compatible modules and their configuration to systemjs-builder.
There is now a webpack integration which runs webpack as a step in the build, hopefully enabling people to use webpack for its awesome development experience, but still use Assetgraph-builder for its configuration simplicity.
I’m hoping we can find more common interfaces between build systems so there could be future hooks for Browserify, Gulp, Broccoli and all the build tools I have forgotten about. The webpack community is making great efforts to try to get cross community collaboration going and I have to applaud that.
What does the future look like for Assetgraph and web development in general? Can you see any particular trends?#
For Assetgraph I have a number of hopes for the future. First of all I would hope that Assetgraph-builder will become a recognizable name in the community and that the builder sees some adoption. Maybe not for large complicated web apps where people have already dug deep and invested in other build setups, but for simpler static pages like blogs. Assetgraph-builder is extremely well suited for being run on the output of Jekyll, Harp and all the myriads of other static site generators.
I hope Assetgraph will become a driver of more than just build tooling. Using the full knowledge of all site dependencies I could easily see it become the engine that drives HTTP2 push in a server middleware, the engine of an editor plugin that lets you navigate site dependencies and informs auto suggest in a better way.
The crawling ability of Assetgraph is something I already used to create hyperlink↗ a hyperlink integrity checker, but I see many more similar applications where tools could extract and test external information.
I am really excited about the movement behind Service Workers and progressive web apps and I see great things happening in that direction. I really hope that the web can start displacing many of these webview and CRUD apps that live in the app stores, while the open web could do a better job with discoverability and delivery. I want to make that happen, so I focus on keeping Assetgraphs static analysis up to speed with all the new specs.
I am excited about the React movement. I hope that it will somehow be possible to adopt some of these techniques into more standardized practices. I had great hopes for Web Components, and I still like the idea, but the simplicity of React’s model of composition and declarative UI just wins big for me.
Build tooling wise I see a continued trend of working with development in a very fragmented way where source code is written to not work without a build tool, and the build tool is required to assemble the bits before you have a working web page. This makes me sad.
In an ideal world we would move towards making the code work in the browser runtime without any external build tool dependencies. That would be a great step towards simplifying web development for newcomers, which I think is very important.
What advice would you give to programmers getting into web development?#
Focus on the basics before you join one of the many hype trains.
Learn HTML. Not just the bare minimum, but all the tags and that they have accessibility implications. This is a fundamental building block that can’t be skipped.
Learn JavaScript. Not ES6 and Babel and transpilers and Gulp and watchers and that whole mess. Just ES5 that works in browsers and Node.js. When you have the basics down it’s easier to understand what all the fuss is about when Hacker News explodes in awe of some new play toy that might do one or two things different from the rest of the frameworks.
Learn CSS. Not some methodology. “Just” how layout works. When I put quotes around that it’s because I think CSS is actually the hardest web technology of the three to learn and master. Pushing pixels just right is tough! Understand that most of the different methodologies are mostly about creating globally unique selectors that don’t conflict through the cascade, and all that crap is side-stepped if you use locally scoped CSS with web components, CSS in JavaScript or CSS components.
Ask a lot of questions and engage with the people who help you find the right answers.
Contribute to open source projects you use. In the beginning a contribution might just be asking a question about missing documentation in a GitHub issue. Then help document it. Eventually you might find a bug you can fix or a feature you can add, but start slow and get a feel for it.
Work in the open. It’s really daunting letting other people see your code, especially when you are just starting out. But it makes you a better programmer in the end.
Who should I interview next?#
Sune Simonsen↗, who has authored an incredibly powerful assertion library called Unexpected↗. His views on testing and his continuous work on improving the testing experience is what finally got me excited about testing front-end code. It has improved my programming skills immensely, so I hope other people can find similar inspiration and start using his really awesome assertion library.
Conclusion#
Thanks for the interview Peter! I’ve dealt with graphs myself in the past in other context (Blender↗ node editor) and can appreciate the approach. It’s a good abstraction and it fits web development well.
You can learn more about Assetgraph at the GitHub↗. Check out also hyperlink↗ and AssetViz↗ to get more insight into your site or application.